-
Products
- SAS - Singalarity Authentication Server & Token Management Server
- TAE - Troubleshooting Analytic Engine
- FSOC - Forensic Security Operations Center
- ST Engineering Data Diode - Secured Data Transfer Gateway
- Rnext - Business Management Platform
- Rnext - QRPay Intra-Gateway
- Rnext - Fintech Solution Platform
- Services
- Industries
- News & Analysis
- Opportunities
- About us
-
Products
- SAS - Singalarity Authentication Server & Token Management Server
- TAE - Troubleshooting Analytic Engine
- FSOC - Forensic Security Operations Center
- ST Engineering Data Diode - Secured Data Transfer Gateway
- Rnext - Business Management Platform
- Rnext - QRPay Intra-Gateway
- Rnext - Fintech Solution Platform
- WaaS x BlueShield - Mobile application protection platform
- Services
- Industries
- News & Analysis
- Opportunities
- Use Case
- About us
How can companies defend against adversarial machine learning attacks in the age of AI?
The use of AI and machine learning in cybersecurity is on the rise.

The use of AI and machine learning in cybersecurity is on the rise. These technologies can deliver advanced insights that security teams can use to identify threats accurately and in a timely fashion. But these very same systems can sometimes be manipulated by rogue actors using adversarial machine learning to provide inaccurate results, eroding their ability to protect your information assets.
While it’s true that AI can strengthen your security posture, machine learning algorithms are not without blind spots that could be attacked. Just as you would scan your assets for vulnerabilities and apply patches to fix them, you need to constantly monitor your machine learning algorithms and the data that gets fed into them for issues. Otherwise, adversarial data could be used to trick your machine learning tools into allowing malicious actors into your systems.
Most research in the adversarial domain has been focused on image recognition; researchers have been able to create images that fool AI programs but that are recognizable to humans. In the world of cybersecurity, cybercriminals can apply similar principles to malware, network attacks, spam and phishing emails, and other threats.
How Does Adversarial Machine Learning Work?
When building a machine learning algorithm, the aim is to create a perfect model from a sample set. However, the model uses the information in that set to make generalizations about all other samples. This makes the model imperfect and leaves it with blind spots for an adversary to exploit.
Adversarial machine learning is a technique that takes advantage of these blind spots. The attacker provides samples to a trained learning model that cause the model to misidentify the input as belonging to a different class than what it truly belongs to.
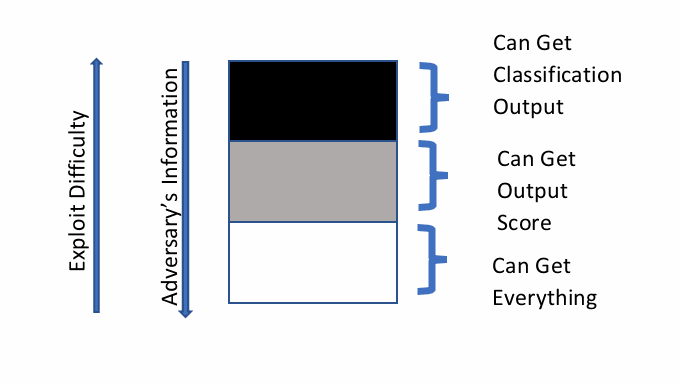
What Does the Adversary Know?
The sophistication of an attack and the effort required from the adversaries depends on how much information attackers have about your machine learning system. In a
Types of Adversarial Machine Learning Attacks
There are two primary types of adversarial machine learning attacks: poisoning attacks and evasion attacks. Let’s take a closer look at the similarities and differences between the two.
Poisoning Attacks
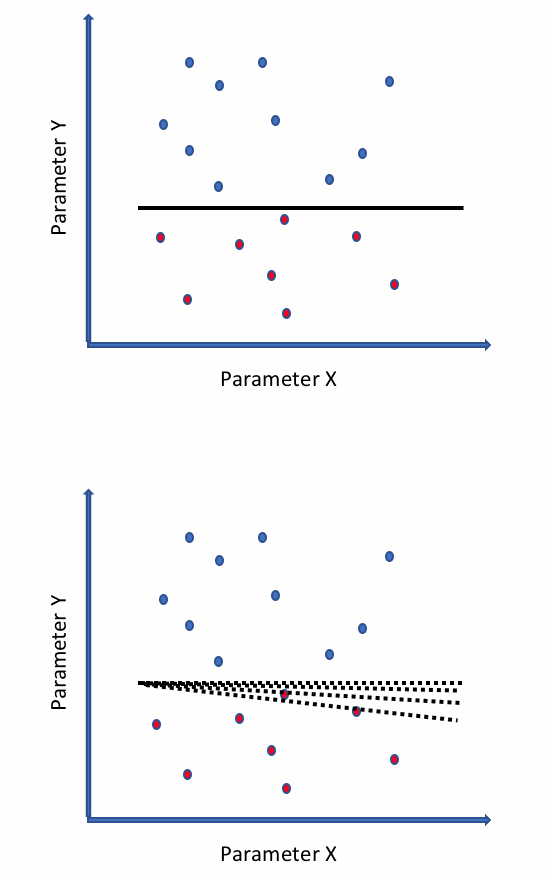
This type of attack is more prevalent in online learning models — models that learn as new data comes in, as opposed to those that learn offline from already collected data. In this type of attack, the attacker provides input samples that shift the decision boundary in his or her favor.
For example, consider the following diagram showing a simple model consisting of two parameters, X and Y, that predict if an input sample is malicious or benign. The first figure shows that the model has learned a clear decision boundary between benign (blue) and malicious (red) samples, as indicated by a solid line separating the red and blue samples. The second figure shows that an adversary input some samples that gradually shifted the boundary, as indicated by the dotted lines. This results in the classification of some malicious samples as benign.
Evasion Attacks
In this type of attack, an attacker causes the model to misclassify a sample. Consider a simple machine learning-based intrusion detection system (IDS), as shown in the following figure. This
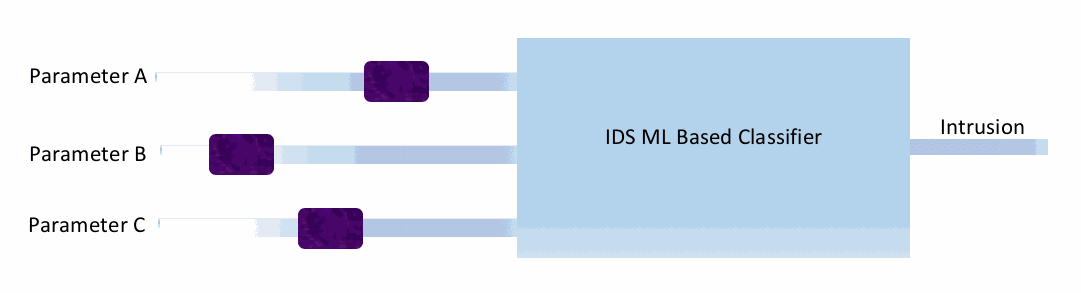
If this is a 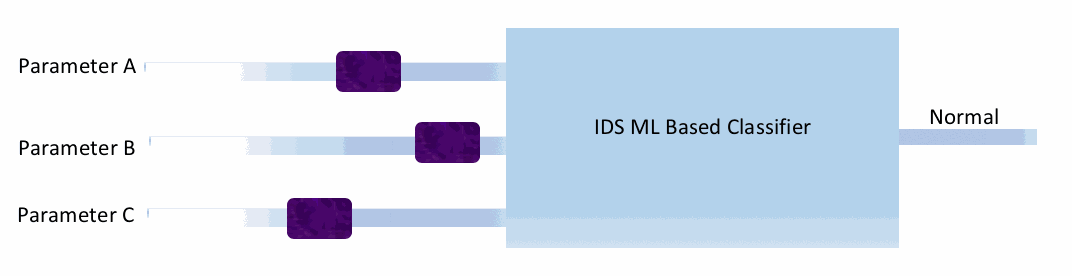
How to Defend Against Attacks on Machine Learning Systems
There are different approaches
- Ensure that you can trust any third parties or vendors involved in training your model or providing samples for training it.
- If training is done internally, devise a mechanism for inspecting the training data for any contamination.
- Try to avoid real-time training and instead train offline. This not only gives you the opportunity to vet the
data, but also discourages attackers, since it cuts off the immediate feedback they could otherwise use to improve their attacks. - Keep a ground truth test and test your model against this set after every training cycle. Considerable changes in classifications from the original set will indicate poisoning.
Defending against evasive attacks is very hard because trained models are imperfect, and an attacker can always find and tune the parameters that will tilt the classifier in the desired direction. Researchers have proposed two defenses for evasive attacks:
- Try to train your model with all the possible adversarial examples an attacker could come up with.
- Compress the model so it has a very smooth decision surface, resulting in less room for an attacker to manipulate it.
Another effective measure is to use
According to a Carbon Black report, 70 percent of security practitioners and researchers said they believe attackers are able to bypass machine learning-driven security. To make machine learning-based systems as foolproof as possible, organizations should adopt the security best practices highlighted above.
The truth is that any system can be bypassed, be it machine learning-based or traditional, if proper security measures are not implemented. Organizations have managed to keep their traditional security systems safe against most determined attackers with proper security hygiene. The same focus and concentration
Source:
Share: